
Everything you need to know about Windows logons in one blog series – the final instalment (for now).
I have threatened on several occasions now to do a follow-up to my previous article on Windows logon times which incorporates the findings from my “logon times masterclass” that I have presented at a few events. The time has come for me to turn these threats into reality, so this series of articles and accompanying videos will explore every trick we know on how to improve your Windows logon times. As many of you know, I work predominantly in Remote Desktop Session Host (RDSH) environments such as Citrix Virtual Apps and Desktops, VMware Horizon, Windows Virtual Desktop, Amazon Workspaces, Parallels RAS, and the like, so a lot of the optimizations discussed here will be aligned to those sorts of end-user computing areas…but even if you are managing a purely physical Windows estate, there should be plenty of material here for you to use. The aim of this is to provide a proper statistical breakdown of what differences optimizations can make to your key performance indicators such as logon time.
This series of articles is being sponsored by uberAgent, because the most important point to make about logon times is that if you can’t measure them effectively, then you will never be able to improve them! uberAgent is my current tool of choice for measuring not just logons (which it breaks down into handy sections that we are going to use widely during this series) but every other aspect of the user’s experience. All of the measurements in this series are going to be done via uberAgent, and as it comes with free, fully-featured community and consultants’ editions, there’s absolutely no reason that you can’t download it and start using it straight away to assess your own performance metrics. I’ve written plenty about uberAgent on this blog before, and I stand by it as the best monitoring tool out there for creating customized, granular, bespoke consoles that can be used right across the business. I’ve recently deployed it into my largest current client, so you can be sure I am putting my money where my mouth is – if it didn’t do the job, I wouldn’t have used it for my customers, simple as. It now features full Citrix Cloud integration and a “user experience” score to tell you where your users are having issues, so go and try uberAgent right now – you won’t regret it!

Part #11 – how low can we go?
So, we’ve covered most of the major components of the logon process, and pointed out a number of tips and tricks around reducing it further. To close this off (at least until we get around to doing some Windows 11/Server 2022 testing, anyway), let’s have a look at what all of these optimizations together can do for you.
But first – let’s remind ourselves why monitoring is so important when we are talking about any key performance indicator, not just logon times.
Investigating user issues
Solid monitoring helps you out on so many levels. You can proactively see if your users are having problems, and you can verify whether what they are reporting is borne out by the data. uberAgent is a key part of my troubleshooting process – whenever I have a user with issues, I can use that to pinpoint the problem and help them out more quickly by adopting a data-driven approach – no more guessing what their problems are! And when you are trending and baselining your data out over time, you can simply glance at a dashboard and see if anything is affecting your user experience, before drilling down into it.
As an example, let’s take a hypothetical user running on Server 2019 RDSH using Citrix UPM. Because we are using uberAgent to monitor the sessions, we know what a “healthy” logon time looks like. We’ve established that the usual baseline is around 25 seconds.
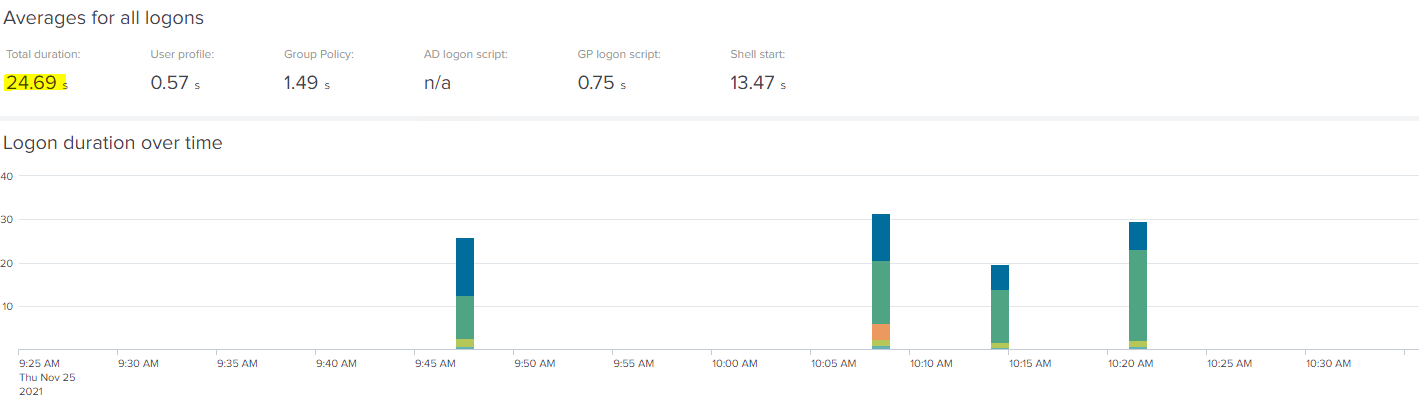
Now, if our user suddenly contacts the helpdesk and says that his logon seems to be taking longer than normal, we don’t have to take his word for it – we can simply look at the data and see if there is anything untoward happening. Analyzing the logon duration KPI shows an uptick of around 5 seconds on average.
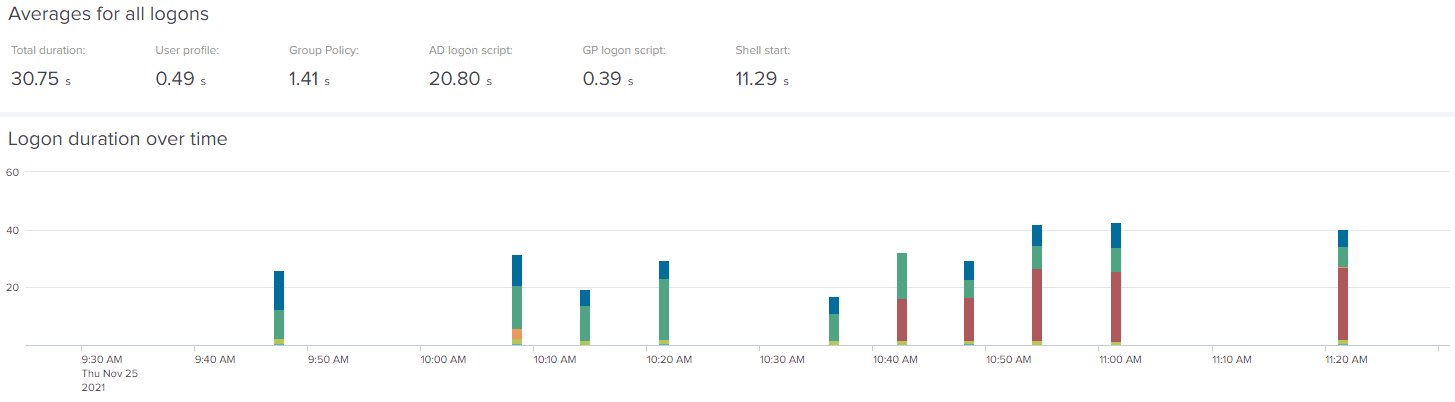
However, we can fine-tune our investigation further, by moving the “start time” of the data set to 10:37 (which was when our hypothetical user noticed their issue). Now, the uptick is far more pronounced than simply 5 seconds – it is over 10 seconds longer, on average.
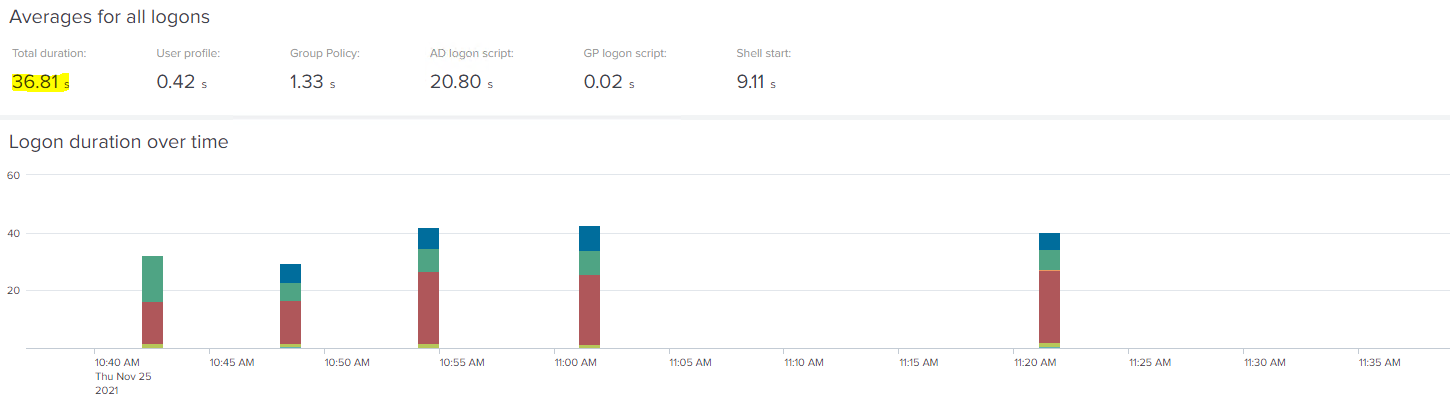
It’s quite clear what has happened, as the breakdown of the logon process shows, but just in case it wasn’t so clear, you can also easily spot that the red section has suddenly come to prominence, whereas it wasn’t when the logon was “healthy”. So a quick look at the legend tells us what the red refers to
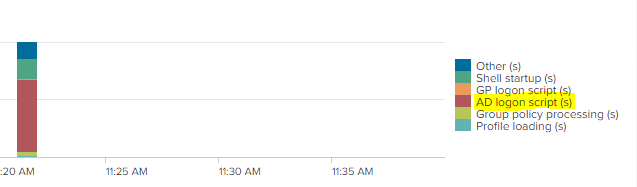
Just as an addendum, you can also drill into each individual logon for further details and breakdown, assuming that they aren’t clear from the summary view (the image below is quite truncated – there’s a lot of detail in the drill-down option)
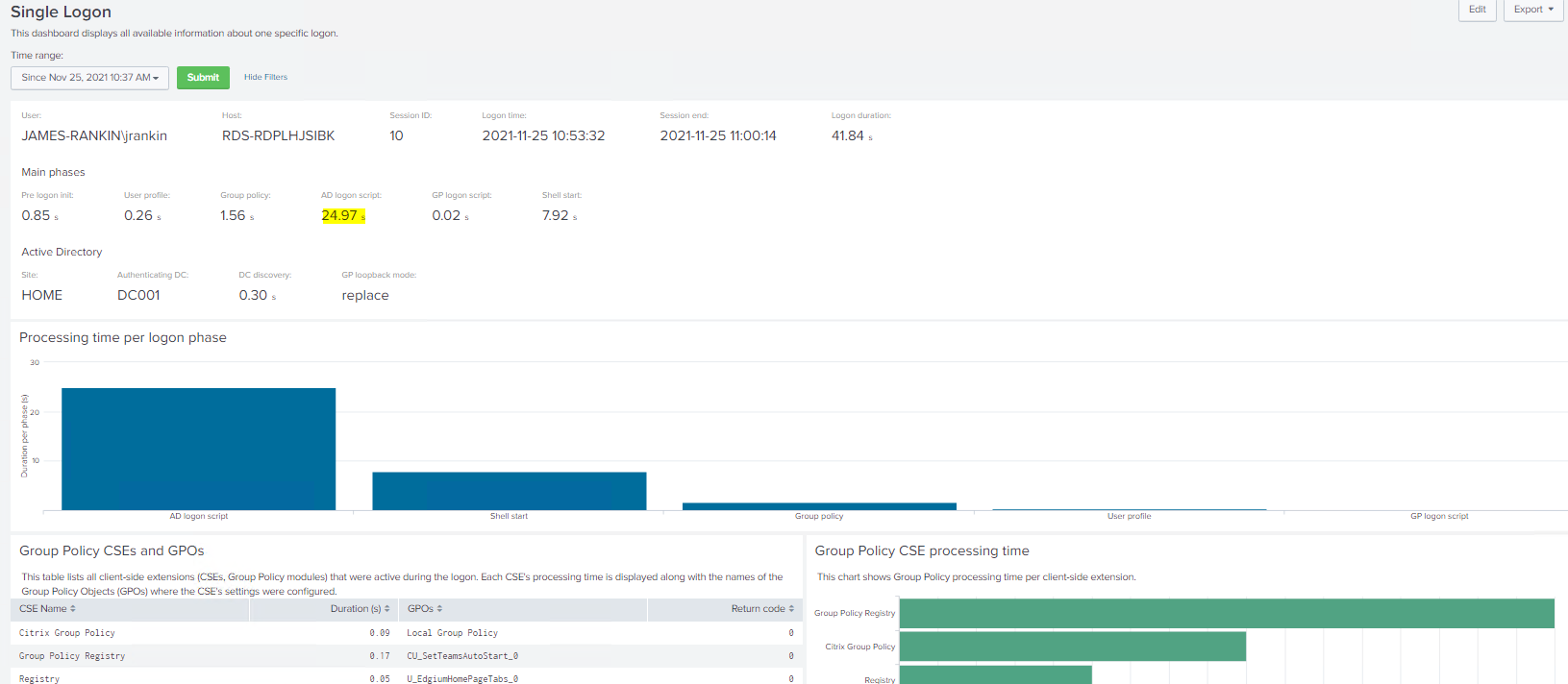
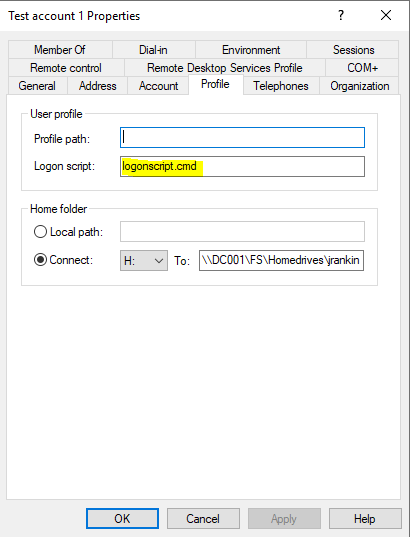
As I said, it’s fairly obvious what has happened here – someone has applied a logon script to this user. However, we can also see from uberAgent that it’s not a Group Policy logon script (as that would be shown in orange), but an AD logon script defined on the user object (as this is what the red refers to). What we simply need to do is remove this logon script from the user (and obviously castigate whoever has applied it).
As I said, this is an easy example, but it goes to show that we should always take a data-centric approach to baselining, trending and troubleshooting. You can use that monitoring data in realtime to identify or support issues that are happening within your estate. Obviously, the scale will always be bigger in an enterprise environment, but the principles remain the same.
For every change you put through your testing processes, the stats should be checked for each of your pertinent KPIs. If you were to install a new or updated security agent, for instance, does this create an uptick in logon time or any of your other key performance indicators? If it does, you can resolve it in the test environment and avoid issues for your user base.
Maximum optimizations
So this is the bit you’re all waiting for, I guess – how far can we actually reduce the logon times?
Firstly, we’re not going to go crazy here. It would be easy to simply create a ludicrously cut-down instance with no applications and no policies and have an incredible logon time, but that doesn’t reflect reality. So I’ve taken a standard Windows published desktop running on Windows 10 21H1 and Server 2019 RDSH for testing, and I’ve given both of them a pretty resource-scarce config of 4GB RAM and 2 vCPUs (yeah, an RDSH instance with 4GB RAM!) Onto it, we’ve loaded a core set of applications including Office, and added thirty-five App-V packages and four MSIX packages. We’ve applied a standard set of GPOs to each (including both Computer and User config items), although we have obviously tried to optimize these. I’ve also set both OneDrive and Teams to start automatically, as you would in a “normal” user configuration.
Also, if you were to use a local profile you’d achieve fantastic logon times, but because that would again be unrealistic for virtual environments we’ve made our test beds fully non-persistent. We’ve used FSLogix for the profile management piece, and the latest Citrix VDA for delivering the desktop. Windows Defender is being used for the antivirus solution.
Optimizations-wise, we’ve rationalized our GPOs as much as possible and enabled asynchronous mode, we have stored both the VMs and the profile share on SSD, we’ve run BIS-F as part of the image build, set up auto-logon for the Windows 10 instance and also applied DelayedDesktopSwitchTimeout, we’ve checked the Windows Defender configuration to ensure all exclusions are in place, ActiveSetup has been removed as part of the build pipeline, and we’ve analyzed all running services and tasks to ensure we are operating as lean as we can without affecting performance. Obviously, on Windows 10 I’ve removed all the UWP app packages as well.
Once all this is done, what sort of data do we get?
Here’s the average logon time for the Windows 10 non-persistent VDI:-

Hard as I tried, I couldn’t get it below this without removing things that users would rely on (such as Teams and OneDrive). However, for a non-persistent instance, this is still pretty awesomely quick – averaging just under 9 seconds in total.
Now, here’s the data for Server 2019 RDSH desktop:-

Now, excuse me if I’m slapping myself on the back here but that is pretty freaking awesome. Let’s consider that this is a non-persistent desktop (I’m happy to record a video of it if people don’t believe me!) and also that it is running on a Server OS with a measly 4GB of RAM assigned to it. The only caveat I would put on this is that there were no other active users on the RDSH VM when we took these measurements, but even so, achieving a Citrix published desktop logon time of under 6 seconds with a full set of enterprise applications is absolutely excellent, and makes me feel like the last eighteen months of logon investigations might have actually been worth it after all 🙂
What’s the secret to achieving logon times like this? Storage is a big difference – particularly putting the profile shares onto fast storage, this makes a huge impact. Asynchronous GPO processing is another biggie, this also has a significant effect. But mainly – I hate to go on about it, but understanding the logon process and being able to break the data down are the most important points to concentrate on. Each enterprise’s logon process is unique, because so are their estates and application sets, and you need to have a view into that in order to work out where the bottlenecks are and where you can make the time savings.
As I said in part #1 of this series – it’s important to set realistic goals. Aiming for logon times that are under ten seconds is a noble goal, but as already mentioned, under twenty seconds is quite passable. Don’t fall into the trap of becoming obsessive about it (which is quite rich coming from someone who’s spent well over a year looking at logons in his spare time).
If there’s one thing I can really leave you with as part of this series, it’s probably to reiterate that managing KPIs like logon times is not something you can simply fix and move on – it’s an ongoing process. As software updates more and more quickly, as new versions of applications and operating systems come out, as agents layer themselves more and more into our builds, it is very important to approach the management and tuning of your images as a constant process rather than a one-shot deal. The more automation you can introduce into this, the easier it will be. And part of that automation should always include installing a reliable monitoring system and constantly using that data to drive the decisions you make.
We may revisit the logon times subject from time to time as new Windows versions arrive and new tricks are required to handle it, but for now, there’s hopefully enough content in the eleven instalments to make a difference to even the nastiest of environments. As always, feel free to send me queries in the comments and once again, thanks for supporting this site and a special mention to uberAgent for sponsoring this logon times series – say thankyou to them by going over to their site and downloading a trial version of their software!
![]()
Amazing content, thanks! I loved it. You’re right…hunting for the fastest logon times is a popular sport for someone, but often the other important goals are getting out of focus… Nobody celebrates you by putting the logon time from 31 to 28 seconds. Balance is key.
Where is the article for windows 2019 optimizations? I see various parts, but no part 1?
All of these optimizations, except where noted, should be able to be applied to any modern Windows version
Hi James,
Explendid work!
Thank you a lot for your contribution!
Regards
Rui