
This post is sponsored by Goliath Technologies, a company that offers end user experience monitoring and troubleshooting software, with embedded intelligence and automation. I did a webinar with Goliath recently talking about the effects of COVID-19 – you can view the replay here.
The remote working catalyst – COVID-19
The COVID-19 outbreak has had a dramatic effect on the IT industry. It could be argued that it’s done more for digital transformation than any amount of projects we have seen come and go over the last ten years. In my own personal area, I saw first-hand the panic that set in as we realized we’d have to transition thousands of users to a remote working model we simply weren’t equipped to embrace.
Like many out there, I was involved in a “traditional” environment that had grown up through many years of expansion. Users in offices, devices on desks, datacenters full of resources that the users connected to through dedicated network links. Those users that were remote operated over VPN links that connected them into the corporate network. Lead times for new equipment were long, processes were drawn-out and time-consuming, and the entire IT operation was designed to support a static, slow-moving user base with minimal remote capabilities. But let’s be honest – despite the obvious drawbacks, the model worked pretty well for the environments that it was designed to serve.
COVID-19 flipped all of this on its head, and flipped it pretty damn quickly. Suddenly that old VPN had to accommodate thousands more users than it was ever designed for. External partners suddenly needed connectivity despite not being allowed to use unmanaged devices. The coronavirus lockdown changed this so rapidly – and on a sliding global scale – that the first lesson that you need to learn about dealing with this is that to fail to prepare, is to prepare to fail. With hindsight, a lot of companies turned out to be in the same boat, but the lesson has to be learned – never get caught on the hop again.

What do we need for successful remote working?
The requirements for our unprecedented move towards a remote working model are laid out here.
- Firstly, the solution needs to scale up (and down, possibly) at a very rapid pace
- All of the required user applications need to be available
- Performance needs to be as good as, or better, than the current solution in use
- Security needs to be very tight, especially when users are using unmanaged devices
- User support needs to be easy to access and thorough – users have no peers to consult with in a remote working situation
This all sounds very typical and probably “blue-sky”, but that’s the approach that we need to take. Each of these requirements has probably existed to a lesser degree in more “traditional” environments, but as we move to a more “fully remote” model, then they take on extra importance.
Fortunately for this particular estate, I already had a small project in-flight that ticked some of these boxes. I’d been working on a solution for a few hundred offshore developers and it already featured public internet access, multi-factor authentication, network segregation and dedicated application connectivity – as well as a rapid-scaling mechanism. So some of the hard yards had already been done, provided we could cover the other requirements as well. Could we use this as the blueprint to support tens of thousands of remote users?
Rapid upscaling
I’m not going to dwell too much on this process, because I think it deserves a detailed blog post all of its own. But for the bare bones of the solution, we used Packer, Chocolatey, AppVEntiX and FSLogix. What were the key advantages of this approach towards rapid scaling – and others amongst our requirements?
No patching required
This was a massive win for me. Because we used Amazon’s “golden AMI” – the full-patched machine image released each month from AWS – we didn’t need to do any patching at all. We had to do compliance scans after initial provisioning, but this was generally all. Not having to patch saves admins so much time!
All core apps automatically updated
Using Chocolatey with the “evergreen” switch allowed us to always install the latest version of any core apps from Chocolatey’s online repositories – so no more updating our own file stores and creating new packages!
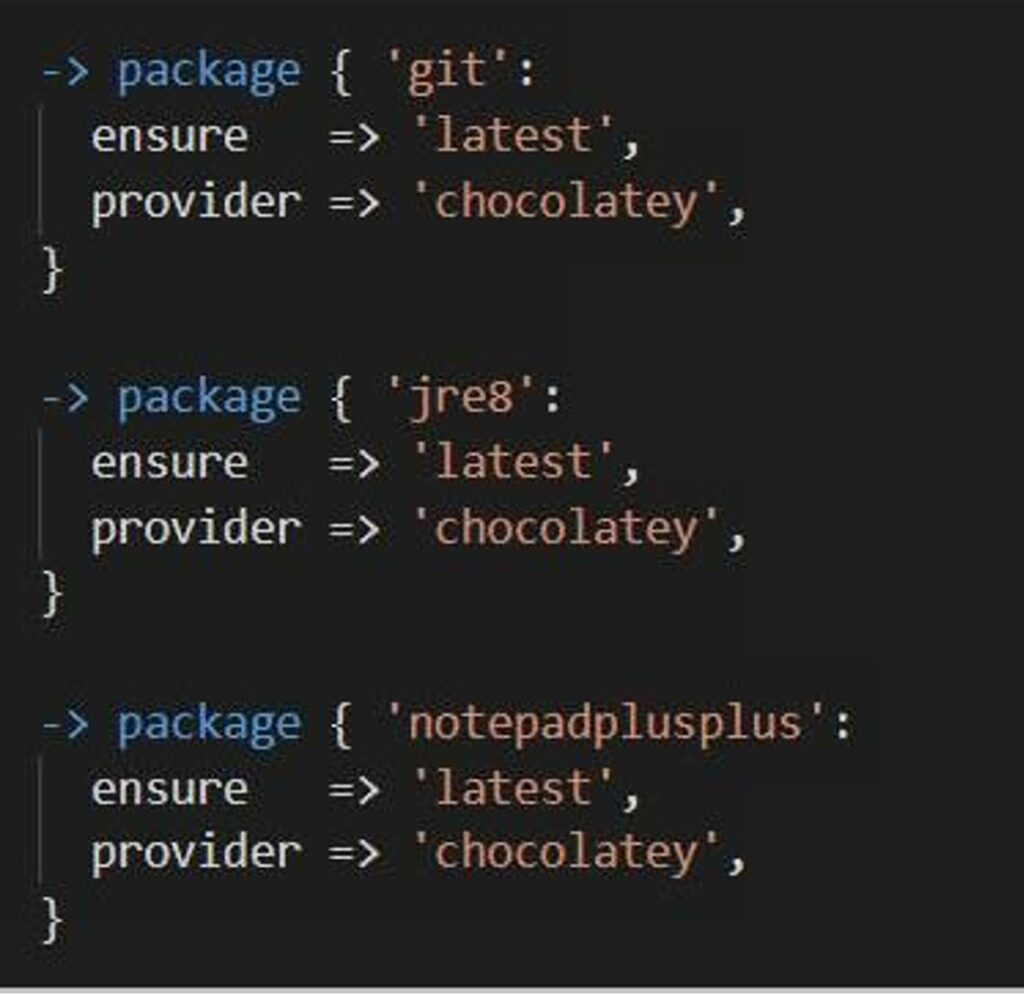
Rebuilt every 30 days
For security purposes, every single worker is torn down each month. So again, no need to deploy updates beyond this period – everything is rebuilt from the new golden AMI
Deployment of non-core apps on-the-fly
Using AppVEntiX (again, a separate blog post will be coming on this subject) allows us to update non-core apps at any time (even during user sessions) just by updating the central share
Single image
Using this combination of deployment techniques allows us to run one single image for all use cases
Application security controls
FSLogix App Masking on top of Chocolatey and AppVEntiX provides the security layer for sensitive apps, and enables the single image
User environment setup done on-the-fly
PowerShell scripts deal with environmental setup – branding, wallpaper, default profile, Start Menus, etc. – rather than relying on policies or external dependencies like file shares
Margin for error reduced
Automating as much of the process as possible significantly reduces the potential for build errors and failures
This method doesn’t have to be confined to workers – we also used it for infrastructure servers too (although the complexity of the infrastructure-as-code required for these servers is significantly less than the workers, due to the lesser volumes of applications).
Rapid testing
As well as being able to scale rapidly (we could deploy at something close to 1080 workers/hour), it is also important in these situations to accelerate testing. It’s important to be able to do load testing very quickly but also the development and UAT areas of your application testing needs to be accelerated. You can look at various methods of automation around this also (there are many methods of doing this, and I will blog about some of them soon).
User application availability
Getting all your applications available can be a lot harder than it should. The first problem is – do you know exactly what your users are running? And how do these applications interact with each other?
This is a very tricky subject, and one I keep coming back to, but this is where EUC monitoring is so important. Without it, you have no chance of knowing every application your users use, but also, how do they interact, how are they delivered, what problems do they face – the list can go on and on. This is where proactive monitoring is king. Without that deep visibility into your estate, you are reduced to asking users and administrators what they know of or have documented – and you can absolutely guarantee that won’t cover everything!
There is so much you could want to know about every application in your estate – the diagram below shows the “perfect” amount of information, so the more you can find out the better. Monitoring can only go so far – it can’t tell you vendor support posture, or business importance, for instance – but it can certainly help get all the technical details and leave the more “human” ones to your business analysts.

To provide users with all their required applications, and also to continually proactively monitor performance and track security issues, good monitoring, auditing, baselining and trending is UTTERLY VITAL. This is where you need technologies like Goliath – but that’s not me saying that for any selfish reason; anyone who has ever seen any of my presentations will realize this is a drum I bang CONSTANTLY. There’s no use designing a beautiful solution only for it to fall down because you don’t understand what is happening within it and how to respond to it.
So the second key takeaway is – you can’t have enough monitoring, but it is very important to make sure you configure it so that you have sensible, actionable data, that you have this monitoring all through your test, UAT and pre-prod environments, and that you aren’t generating an overload of data. Monitoring is important in every situation, but the COVID pandemic makes it doubly important because we are almost totally reliant on it as an indicator of problems within your solution.
Onboarding
One of the biggest changes during the COVID pandemic that we saw was around user onboarding. I think, personally, this was one of the biggest challenges, particularly with a globally diverse user base. First of all, we made sure we set up a dedicated team that were equipped specifically to deal with user onboarding to the remote solution, and that the contact details for this team were inserted into the initial communications around the platform, onto the Citrix Workspace page, and the actual published desktop background as well. This was something which couldn’t be done enough – users needed to know that they had support and how to access it.
Remote working – the cultural shift
Also, let’s not forget that remote working, for a lot of people, is something of a “cultural barrier”. One thing we quickly realized was that user guides and Frequently Asked Questions documents, even when linked at easily accessible locations, were not read by the majority of users. What we found that people respond to are quick, to-the-point, punchy video guides. I’ve fallen in this trap previously a few times on my YouTube channel – spending a long time waxing lyrical about a subject trying to cover every possible eventuality, and going through a very long end-to-end demonstration. This doesn’t resonate with people at all, when it comes to building up their confidence and capability with a new solution. They want something short, direct and to-the-point that shows them the pertinent points quickly and with a minimum of fuss. Most UI tools are pretty intuitive anyway – users just need something that points them in the right direction. We found this was a great tool – quick, professional looking instruction videos are far easier to make than you might think. If you have any team members even vaguely familiar with technology like Camtasia or Adobe AfterEffects, get them to start making how-to videos straight away. In a world where we can’t visit users or are under pressure so can’t spend the time with them on a call doing a step-by-step walkthrough, video tutorials are absolutely invaluable, and we got great responses to this which really accelerated the onboarding processes. Two things we really concentrated on were videos that showed users how to sign up for and use MFA, and checking that their USB devices (such as headsets) were all correctly connected and detected. These two areas cut down on a multitude of common helpdesk calls – which we identified by crunching the data we were receiving based around the users that we had already had using the system ahead of the COVID-19 response. Monitoring again is vital, this time to understand what the problems were that commonly affected users, and allowing us to target these common issues for collateral that could help them.

Once you’ve given your users collateral and a dedicated support team, then what you need to do is also understand how the role of this support team has changed. They need to be more comfortable with thinking outside the box when it came to user issues. The paradigm shift comes with problems that are now more to do with the user’s internet-service provider or their local setup, rather than our infrastructure. One of the things we’ve noticed is that people have often got kids at home and they’re also often sharing a connection with workers from other companies. They’re all contending on the same broadband – and if everyone’s logging on in the morning at the same time, then the ISPs are under pressure. The role of the first responders, in this case, becomes to often to find quick, workable solutions to connectivity challenges. Dealing with wifi interference, helping users run wired connections, switching to tethering, etc. – all things that the support team need to adapt to. For our users at home in India we saw horrendous challenges with very poor connectivity, and there was no way that support teams should have wasted any time on even trying to troubleshoot under-performing Citrix sessions in the “traditional” way given the horrendous network performance.
Self-help tools and dashboards
Another great help we found helpful in this situation was to publish tools within the user session to monitor their network connectivity and help them identify if there were any issues they could self-help with. We combined the HDX Monitor within the session with use of speed testing tools on the client (again, backed up by quick and punchy video tutorials) to allow users to assess whether they had network issues. Working in conjunction with the dashboards (below), this again helped us to improve the service for users.
Dashboards were vital in identifying to the users if there is a service degradation to be aware of. We made public dashboards available that covered the health of all service components and warned if there was an issue ongoing. We aggregated things together here like the Citrix Cloud service status dashboard to give an overview for both the users and the administrative teams, so that they could see if an outage was in progress and what the potential downtime and effects would be, along with possible timescales for resolution.
Also something we’d tried to do, because it would really help our users, is expand the capability to self-service basic Citrix issues (such as check for orphaned sessions and disconnect them). For our full-fat VDI users, we gave them the option to initiate restarts of their devices from the workspace portal (because these are dedicated one-to-one instances), but we also added things like BGInfo (which you can heavily customize) to help with troubleshooting that we never did before, but really we’d like to expand this a lot more. Interestingly enough, things like profile self-service resets that enterprises would NEVER turn on before (like the old AppSense tools) were suddenly the flavour of the month – when dealing with huge user uplifts like this (10,000+ in our case), the possible benefits of self-help tools suddenly outweighed any misgivings. With the COVID pandemic, the more self-help tools you can provide (and naturally, back them up with instructional videos), the more difference you can make to the quality of the service for your user base. Resetting other common issues like passwords and MFA tokens (reset of device, or change of device) we also rolled into this.
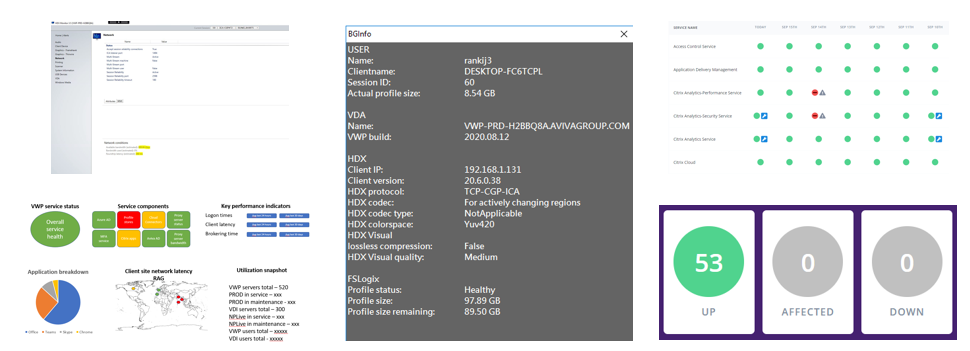
I’m going to keep on banging this drum, but again, the data that we get from monitoring is what drives these tools and the value they can give.
Support standards
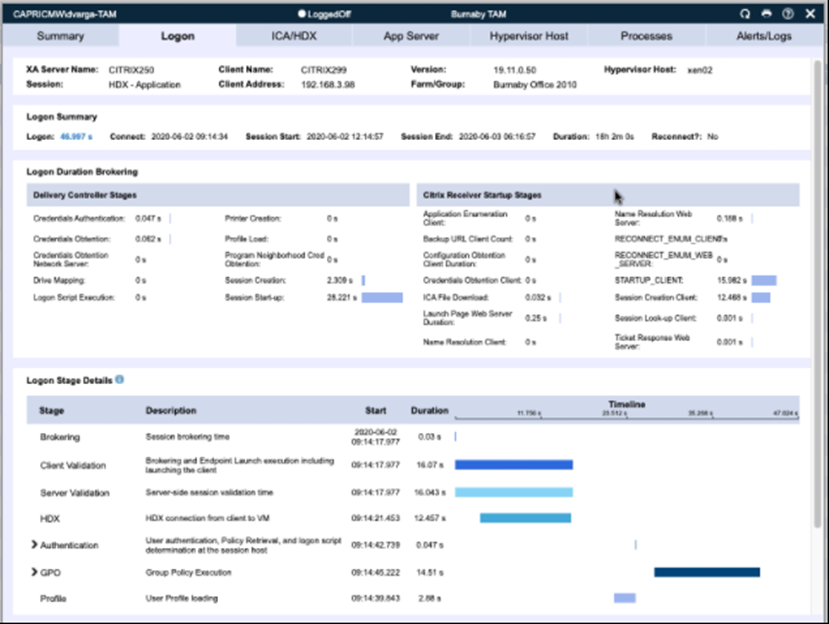
What we also found was that once you open up to users with unmanaged devices, it is very important to set some standards. Can we have users connecting to the remote services we offer using, for example, unpatched Windows XP machines running very old Citrix Receiver versions and no active antivirus?
We had to set some standards, especially in the early days. If you are managing your own NetScalers then Endpoint Analysis can help out greatly here, but if you are in cloud and using Gateway Service we did not have this kind of option (not yet anyway – which is about as much as I can say on that subject). So in order to try and meet our standards, this is where monitoring comes to the fore again. We needed to make sure we always had readily available and accurate data on particular metrics such as connecting OS type and connecting client type. For users calling in with problems, it was essential that we compared their configuration to our baseline standards and insisted that they upgrade to the supported client and OS levels before we could provide support. When it came down to configuration of items like Macbooks, we had to be even more strict as like most support teams, we were a bit lacking in experience around troubleshooting non-Windows client devices. Ipads and Chromebooks, not surprisingly, were much easier for our support guys to get to grips with, but we had be very particular about the update level and client version we saw on connecting Mac devices. It was very important that we had the data available about the connecting user sessions to avoid our support teams getting stuck in very time-consuming loops trying to connect ancient and unsupported systems to our remote working service – and an interesting aside of this is that it helped us spot all the users using the HTML5 Receiver to connect instead of the “proper” Workspace App method.
Enforcement of patch levels and antivirus is still a big issue, though. Citrix policies allow us a certain level of protection in this area, but the spectre of things such as keyloggers on compromised client devices still looms big. We are waiting for features like App Protection to be available in cloud, but those of you using on-premises systems can use it right now. This also speaks to why it is very important to keep Workspace App versions up to date as we see Citrix bringing out more and more security features and we want to be using them as soon as possible. Indeed, in the COVID world Citrix have been pretty good about identifying the security issues that can arise with unmanaged devices and are presenting a good value-add with the new features they have coming through – unfortunately NDA means I can’t speak about them but there is some really useful stuff in the pipeline. More can be done here!
Once more, not to overstate the point, but EUC monitoring tools like Goliath that can see into the user’s client details and the like are vital here. If we can’t see what’s going on, we can’t head off issues like old client versions and support teams waste valuable time and resources troubleshooting an issue that they have every right to simply bounce back to the user.
Session performance
Now, if we’ve got our estate scaled-up, our applications deployed, our users onboarded and working, we don’t need to worry any more, do we? Well – unfortunately, we need to get even deeper now.
The importance of your virtual platform is now HUGE – this isn’t just something users use occasionally within their desktop session for some particular published app, or a way to work from home on very odd occasions – this is now their PRIMARY platform. Any degradation in performance is going to impact everyone across the entire business – maintaining and INCREASING performance is now an absolute paramount focus area. You need to keep an eye on performance levels, particularly memory and CPU (did anybody mention monitoring??? This is really where properly focused EUC monitoring like Goliath can start to give you a big value add) and make sure you can react to problems quickly. Identify the big hitters on your platform (I can tell you them now – Teams and Chrome, trust me), optimize them, tune them, do everything you can to make sure there is plenty of resource and bandwidth available to make sure video calling is absolutely perfect. Your users are now depending on that for so much more than they used to. Some places are hosting virtual meetups, social events and “vBeers” sessions to ensure that users don’t miss out on the face-to-face interaction that they need from work. As IT admins, consultants and architects, we are now also responsible for making sure that users are able to socialize as well as work – pressure, much? 🙂
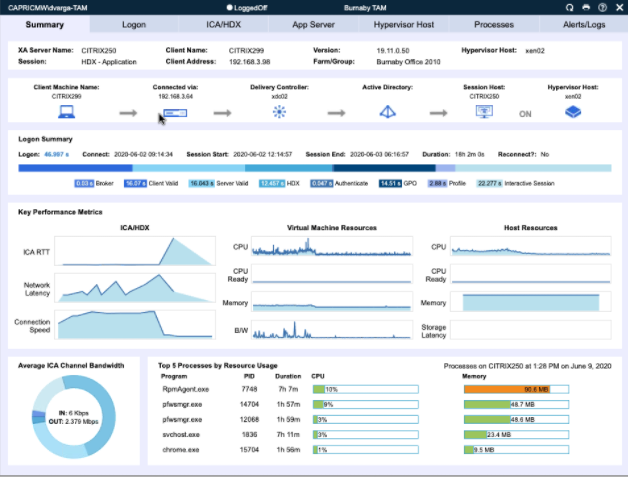
But it’s not just session performance that interests us. You also need to be paying particular attention to how your users are using the platform. Management, naturally, are interested in whether users are active, whether they are productive – but this isn’t just micro-management and the old “I need to see them to know if they are working”. There are new important areas that enterprises adopting a remote workforce need to pay attention to.
Firstly, are working patterns changing? If people are working more in the evenings, then do we need to stand up more infrastructure and provide longer support hours?
Are users working too long? It can be difficult to switch off when at home and it can also be tempting to work longer and harder just to “prove” you’re pulling your weight. Are you users putting themselves at risk of burn-out?
Are there more security incidents? Let’s not forget, COVID offers opportunities to hackers and spear-phishers to take advantage of the confusion and gain access to users. Can we identify potential compromises by looking at user behaviour? Should Dave from accounts really be logging on at 3am and suddenly running PowerShell instead of Excel?
EUC monitoring tools like Goliath offer you not just data but the reports from this data to identify the trends you need to watch. Pay real attention to trends in how users are connecting, make sure they are using up-to-date OSes and client versions, alert them if their network connectivity degrades, proactively monitor the environment for even small changes, as we are now in a situation where every last ounce of performance you can dig out makes a big difference to the users.
Security
Security needs to be built-in from the bottom up, otherwise you will find that you put together a beautiful, performant solution and then security come along and ruin it all for you. Security by default is the key phrase.
Security and usability are generally opposites, so a trade-off is necessary, but don’t forget especially if using unmanaged devices that you need to ensure security. Get users used to it being an integral part of the solution – if they aren’t used to using MFA, for instance, get them used to it. Block that low-hanging fruit – PowerShell, command prompts, WinRM, etc. Make sure you have plenty of detection and logging, and that all your logs are centralized because you will be breached eventually and when you are, you need to track it. Make sure your processes are robust and you can spot anomalies and limit lateral movement like we already alluded to. If you aren’t looking at security already, then adapt your monitoring solution so that you have visibility of security aspects of your environment.
The “new normal”?
So we can see how we’ve had to adapt our processes and people around COVID, but is this change going to be around forever? A customer of mine saved £7 million net on travel costs in three months, and I certainly know one thing – as long as I can, I personally am not going back to the office. Who wants the hassle of commute, who wants to give up being able to mow the lawn or go for a walk in your lunch hour? I know there are some people whose personality, job role or even personal circumstances mean that they may want to go back to the office, but I feel that for the majority, many will not want to go back. And for offshore users – I spoke to one user in India who had saved eight hours a day due to not commuting – who would want that back in a hurry?
If you wanted to be surrounded by the social aspect of work, I don’t see any reason why regional “work hubs” shouldn’t spring up – some enterprising types have even suggested pubs should take advantage of their wifi and provision of coffee and food to become an ideal network of new “work hubs” without having to erect new buildings. In all probability, the “new normal” will probably become most of time at home with fortnightly or monthly meetings with teams in the office…..there are some things that should never be remote (virtual conferences are the worst, I love to meet people there and talk face to face or in groups) and for salesmen and creative types there probably is a lot of value to being in the office – but, for about 80% of us, it could well be the much-vaunted “new normal”. As long as we have adapted sufficiently to this new way of working, I don’t see any reason why we shouldn’t go into the office more than 12-20 days a year. I may be wrong, but I’d love to see city offices abandoned for the most part and we all move to regional hubs and the homeless can all have the offices as new places to live – might be optimistic but I’d love to see this be COVID-19’s legacy. Another important note to make is that our DR approach has totally changed, our old idea of having “backup offices” full of computers and printers and desks have now been completely mothballed and we have adopted our virtual workplace as a full DR method. So even more changes and savings for the business.
But as we move further and further into this brave new world, the importance of understanding, baselining, trending and reporting on the happenings in our environment becomes ever more vital. Using technology like Goliath to gain insights into your new workforce cannot be underestimated. Gathering data, and automating our responses to it, is king. Without it, we might as well be blundering around in the dark, much like we were when we got caught by COVID-19 in the first place. Let’s not allow it to happen again!
Thanks to Goliath for hosting the joint webinar and letting me experiment with their monitoring and reports – feel free to go check them out over at their website.