
Microsoft Teams’ profile bloat is truly awful. Here’s a quick guide to getting around it!
This is a basic runthrough of a problem that I ran into today whilst gathering the data for part #2 of my “ultimate guide to logon optimizations” (and apologies for the delay on getting it out there – paid work and family have an unfortunate tendency to get in the way!)
The Teams mega-bloat
Many of those out there who use FSLogix Profile Containers have noticed that when you run Teams for the first time, there is a HUGE increase in the size of the profile. The confusing thing is, in real terms, there isn’t actually that much of an increase in the DATA in the profile – it all seems to be white space. This isn’t particularly confined to FSLogix Profile Containers, either – if you are using Citrix Provisioning Services, you will also notice a dramatic uptick in the utilization of your write cache when users run Teams for the first time. Now naturally, in an FSLogix environment, this problem is only observed when you are using dynamic sizing for your containers – but I think that is a pretty common configuration, for a number of reasons. Firstly, you aren’t committing all of the storage in one go, and secondly, it is easy to tell whose profiles are getting close to the maximum size limit, as you can actually see how much space has been used.
The reason that FSLogix Profile Containers expand like this is because the VHD or VHDX file that you are using never actually shrinks when space is relinquished. Profile Containers (and Office365 Containers, for the record) expand dynamically but then remain at the “high watermark” level if some of that space is subsequently released. This sounds a bit odd, but when you remember that FSLogix is clever enough to then use that “white space” before it expands the profile further, it isn’t that much of an issue. The same sort of principles apply to the PVS write cache, although as the write cache is a “system” rather than a “user” artifact, the behaviour is not an exact replica. If you’re using FSLogix Profile Containers, you can use any one of a number of shrink scripts to compress the VHD(x) files back down when not in use (I always use Jim Moyle’s script here, although there are many equally good other ones out there in the community) and reclaim that space properly. With the PVS write cache, you simply have to wait until the next device restart in order for that to be cleared out.
You can see the dramatic increase in utilization of the Profile Container through these screenshots. Here is a snapshot of the container after I have logged on to a Windows 10 VDA for the first time:-

Now, after I launch Teams, but prior to logging in, you can see it has expanded somewhat

Once I have signed into Teams properly (as I have to supply MFA), you can now see the increase becomes rather dramatic, to say the least

But once this has all finished, checking the size of the user’s profile (either in use, or by mounting the VHD) reveals a very much lower figure
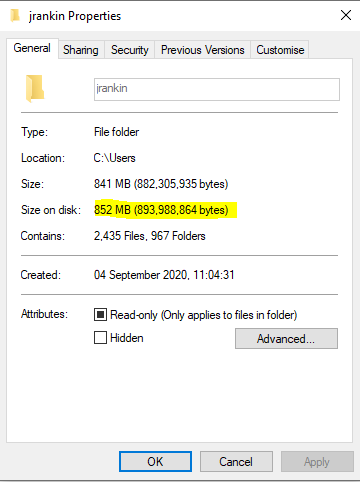
It is clear that something is writing out a huge amount of data, and then removing it. Because of how VHD-based profile solutions (and PVS) operate, this means that storage is being committed, and then left as white space.
But is this really an issue?
Well in basic terms, probably not. Because FSLogix can (and will) use that white space before anything else, you’ve simply dynamically expanded the user’s profile ahead of time. You’re eventually going to use that 4-5GB anyway, so all you’ve done is a premature expansion. In PVS terms, as long as your write cache is sized properly and can absorb the uptick, then you simply have to wait for the next reboot to get around the problem (and on most PVS systems that’s usually somewhere between 24 and 48 hours away, sadly).
But if you’re working at scale, that’s still a helluva uptick. I have one customer who saw a 17TB increase overnight after they turned on the auto-launch for Teams. If you assume some of those users aren’t going to use it much, then that’s a whacking great storage increase to absorb in one go. And this customer also paid for their storage by the GB as part of a managed service, so to swell it by 17TB in one fell swoop was a huge pill to swallow. If there is a cost benefit to the business to be had by reclaiming this storage capacity, then it can be argued that it might be an idea to find a way around this issue.
Also, there is the point that Teams really shouldn’t be behaving like this, ideally. Particularly for situations where technologies like read-only disks are in use, an application that vomits out a huge amount of temporary data and then removes it all straight afterwards isn’t a great fit. In many EUC environments, having a slick, streamlined and predictable core set of applications that fit into your management patterns is vital. Any change in behaviour can result in impact onto other aspects of the service that you are trying to provide.
Fixing it (for now!)
So how do we go about getting around this?
Firstly, make sure you are using the proper machine-based installer, otherwise you will give yourself more problems than just this. This post is a good reference, and contains links to the machine based installer downloads. Make sure you run the installer with the switches specified in the article, as below
msiexec /i <path_to_msi> /l*v <install_logfile_name> ALLUSERS=1
If you don’t get the installer switches right, you will potentially have a horrendous time as the machine-based and user-based installers get into a fight, so make sure you don’t make a mistake! For what it’s worth, there seems to be very little difference in the actual layout of the installer whether you use the ALLUSER and ALLUSERS switches or not. They both simply drop a folder into %PROGRAMFILES(x86)% which then hooks into each new user’s session. I think the only difference between them is how updating is allowed, but I don’t know that for sure – my upcoming CUGC session on Teams with Rene Bigler may shed some light on it though 🙂
Next, I had to go and do some Process Monitoring to try and find out exactly what was spitting out all of this data. However, I was a bit perturbed to find that precisely nothing showed up in my Process Monitor log to do with Teams data.
Fortunately, community always saves you in these situations. Enter Jim Moyle to tell me that the Process Monitor filter driver runs at a different altitude to the FSLogix one, so I would be unable to see what I needed to whilst using FSLogix at the same time. Rather than try and adjust the Process Monitor altitude (it’s a Friday afternoon!), I opted to remove FSLogix instead and repeat the process *normally*.
This time, we could see a lot of activity around the Teams folders in the user profile. Some in particular seemed to be changing their allocated disk space values very quickly, both increasing and decreasing. A look at Process Monitor confirmed this – over 30,000 writes into one particular folder

It appears the culprit is a folder called %APPDATA%\Microsoft\Teams\Service Worker\Cache Storage. I have no idea what this is used for, but it is definitely the source of the huge amount of data being written and then removed. Interestingly, Process Monitor didn’t show a single “deletion” during this time, but I am wondering if the act of overwriting an entire folder’s contents doesn’t log as a “delete file” action per se. Maybe someone a bit more in touch with Process Monitor can tell me 🙂
Now interestingly, the article I linked earlier (https://docs.microsoft.com/en-us/microsoftteams/teams-for-vdi) has a section that is titled “Teams cached content exclusion list for non-persistent setup”. However, this doesn’t seem to be accurate, in my opinion. Certainly the blanket exclusion for *.txt files feels like a weird flex, so be careful if using it.
However, it is clear that to get around this aggressive expansion issue, we need to remove the folders concerned from the profile. Naturally, the way to do this is by using the FSLogix redirections.xml file. Firstly, configure an FSLogix redirections file with the following text:-
<?xml version="1.0" encoding="UTF-8"?>
<!--Generated BY ME FTMALM-->
<FrxProfileFolderRedirection ExcludeCommonFolders="0">
<Excludes>
<Exclude Copy="0">AppData\Roaming\Microsoft\Teams\Service Worker\CacheStorage</Exclude>
</Excludes>
<Includes />
</FrxProfileFolderRedirection>Save this on a network share somewhere it is accessible from all your devices and make sure it is called redirections.xml
Now, configure the FSLogix GPO from Computer Config | Admin Templates | FSLogix | Profile Containers | Advanced called Provide RedirXML file to customize redirections
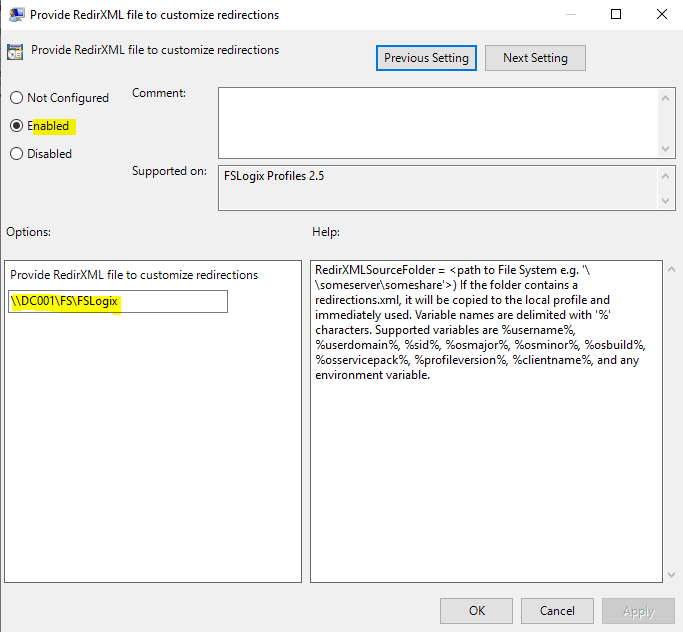
Set this to Enabled and put the value as the folder path (not the full path) to your XML file you saved earlier. The file must be present in this folder and called redirections.xml.
Now update the policy so it is applied to all of the target machines. Next time they log on, the folder specified in the XML file will not be directed into the Profile Container – it will be put into a local folder called c:\users\local_username and discarded when the user logs off. So all of those reads and writes will not be committed to the container – they will be directed locally.
So when we log our user on, run Teams for the first time, sign in – this time, when we have finished, we see a much healthier-looking profile size

Far, far better than the 5GB+ we saw earlier!
In summary, this is a workaround to cover for the bizarre way Teams behaves. In certain circumstances, you may want to avoid this initial expansion of the profile in such a dramatic way, and excluding the CacheStorage folder is the easiest and most effective way to do it.
Bear in mind that you are exchanging that storage hit for a big burst of local I/O as a user runs Teams for the first time, so assess the impact carefully. Unless you are logging hundreds or thousands of users onto Teams for the first time simultaneously, though, the potential for impact in this way should be limited.
Also, as always, be careful of using the redirections.xml file to aggressively trim your Profile Containers storage. FSLogix isn’t comparable to old file-based profile management solutions – leaner profiles do NOT give quicker logon times or make any performance difference. Excluding caches just means you pay the price in performance as everything re-caches at a later time. This particular example is an exception to the rule, because a) the extra storage space can be potentially HUGE, and b) it only happens at first Teams launch anyway, not every session.
This trick wouldn’t make any difference to PVS write cache impact – but again, bear in mind that this only happens at first launch of Teams, not every time, and write caches are cleared fairly frequently. Also, if you are using Citrix UPM or another file-based profile management solution, it wouldn’t hurt to exclude the CacheStorage folder from it.
Thanks to Jim Moyle and Kasper Johansen for their help on this. Also, a quick plug – look out for a session on Teams Deployment On Citrix from myself and fellow CTP Rene Bigler at the Phoenix and New Mexico CUGC event on October 7, time to be confirmed – follow us on Twitter to get the registration details.
![]()
Excellent writeup and analysis. Readers are greatfull to you. Thanks for sharing
Excellent info. Thank you for sharing.
do you have a recommend best practice default FSLogix redirections file, for the diff supported win 10 & WVD ???
This is all I use
$Recycle.Bin excludes which location of recycle bin? as I have deleted some files which are moved to recycle bin but they should not appear on next logon if $Recycle.Bin is set in redirection.xml, unfortunately, deleted files from the previous session are still available on next logon.
Could you please advise what went wrong?
It should stop the $Recycle.Bin hidden folder from the profile root being written to the profile. If they’re still there at next logon, it is writing the deleted files to a different folder.
hi , would it make any sense to exclude its parent folder ?
AppData\Roaming\Microsoft\Teams\Service Worker
thanks
Up to you. If it means that you are seeing a lot of “standard” session activity being sent to the local disk, then maybe not. However if the activity is limited and doesn’t affect functionality, I don’t see why not.
Is there anyway to put similiar logic into Ivanti UWM and the VHD offering they provide
I honestly don’t know. You would need to ask Ivanti support if they provide a method for excluding folders from the VHD.
“Now interestingly, the article I linked earlier (https://docs.microsoft.com/en-us/microsoftteams/teams-for-vdi) has a section that is titled “Teams cached content exclusion list for non-persistent setup”. However, this doesn’t seem to be accurate, in my opinion. Certainly the blanket exclusion for *.txt files feels like a weird flex, so be careful if using it.”
I set the exlude. After that, my fslogix log told me this (sorry, one of the errors is in german):
[16:28:46.784][tid:00000ba8.00000ecc][ERROR:00000428] error.cpp(13): [WCODE: 0x00003b01] (Bei der Verarbeitung der Steuerungsanforderung ist ein Ausnahmefehler im Dienst aufgetreten.)
[16:27:33.596][tid:00000ba8.00000ecc][WARN: 00000000] User session for S-1-5-21-1174508876-2135809228-1566177508-5290 has an unexpected status. STATUS = 200
Also, my profile bloated up because no single redirection worked anymore and the worker was unable to detach the vhdx disk. For me, this exlude also seems weird ;-). Without this exlude or with other excludes recommended in various articles everything is fine.
Regards
Thanks Steffen, that’s good information.
Hello Steffen.
Do you have the message with Office- or Profilecontainer?
I have this error with Office container.
My exceptionlist has the entry AppData\Roaming\Teams\*.txt.
We’re using published Desktops on Xenapp 7 Build 1912 CU1 on W2k16.
Hello Listmaster: Please send this to Steffen, if possible. Thx in advance.
Regards
Dirk Emmermacher
Hi Dirk,
we use the profile container. As far as I know, redirections.xml only works with the profile container. Very interesting, maybe the OS or the fslogix version makes the difference? We are using Citrix vaad version 2006 and FSLogix Agent v2.9.7621.30127 with Server 2016.
Do we need to do no configuration for teams in Profile containers in order to leverage the teams cache redirections using the redirections.xml file ??
BR,
Kumar
No, just configure the GPO to point to the redirections file. No Teams config is required.
Hello Steffen,
We also have the error-message WCODE: 0x00004b01. We get the message when the profile is used by a second session. Our profile type is “Try for read-write profile and fallback to read-only”. Do you have any hints of using the profile in parallel for multiple sessions?
A second session on the same server? Or a different server?
Does it matter if you use the per user install of Teams?
Shouldn’t do, AFAIK
Hello all,
we had huge profiles, after updating fslogix version fslogix 2.9.7621.30127 and defrag and shrink all profiles, we added the exception in our redirection.xml (AppData\Roaming\Microsoft\Teams\Service Worker\CacheStorage), since our storage is not moving more ! and the profiles remain around 2 gigabytes!
hello
slightly off subject
is it common to use MS folder redirection GPO for things like My documents / Desktop along with FSL containers. my thoughts are that fdeploy makes backups easier for users documents. save having to backup the whole container / vhdx
thanks
You can use Folder Redirection, but personally I’d just use OneDrive Known Folder Move now instead
Thanks James.
one last thought.
i presume the custom redirections.xml you have on git hub is fine for a prod environment – subject to appropriate testing of course
dave
I don’t have a redirections file on GitHub. Which one do you mean?
apologies
the xml file was posted by another james
dave
What if you use Office containers?
Yeah, same issue here. Our Office containers bloat when setting the “Save Teams data” in the office365 section.
How can i cleanup teams data in office container?
Simply delete the container, or the folder containing the Teams data.
I mean how to exclude it from growing the vhdx. with profile containers you can use the xml file.
We use AppSense (or GPO) to exclude folders when have Office + Profile container.
Hi thank you for this!
I excluded the Service Worker, but it seems there is no redirection to the local._username folder..
How can i check if the redirection worked? I used the GPO on existing FSXLogix Profiles. Do i have to create a new vhdx for it or does it affect on running profiles also?
Thank you!
It should redirect to the local folder. Check that the file is copied down correctly (I think it goes to the user’s profile).
Hi James, Thanks for this amazing article. I have a quick query, if we apply redirection.xml for the Cache Storage exclusion then does this exclusion will impact the performance of Non-Persistent Citrix desktop?
Thanks,
Quaseem
Shouldn’t affect performance, no.
Hi James, quick question,
We have an AVD solution running FSLOGIX. We run an engineering application that requires the local temp folder to point to “C:\USERS\%username%” as opposed to “C:\Users\Local_%username%” in order for the application to work as designed. I have tried the “SetTempToLocalPath” registry option but that did not seem to do the trick. Any idea if this can be achieved with the “redicretions.xml” file and if so, can you perhaps assist with an example?
Have you tried disabling the GPO that redirects the temp folders to LOCAL_USERNAME?
Hi James, there is no GPO applied in this case from what I could see. We use Nerdio to manage our Azure Virtual Desktop deployments. I tried fiddling with the GPO .admx templates but it appears that they are being disregarded in this case. Hope this helps.
Check the Registry entries on the client at HKLM\Software\FSLogix\Profiles\SetTempToLocalPath and make sure they are set to 0
Hi James,
The redirection seems to work and don’t at the same time.
We can see the redirected Teams CacheStorage folder under “local_username”, but at the same time we also have a similar sized folder in the users’ normal profile folder too in its original location: C:\Users\username\AppData\Roaming\Microsoft\Teams\Service Worker\CacheStorage
Have you seen this before? Do you have any idea what might be the issue?
Thanks.
No, that doesn’t happen to me. I would check the version you are using and if necessary downgrade, that seems wrong.
Thanks for the prompt response. Do you know what is the last working version for the redirection?
We are on 2.9.7979.62170.
I don’t know that redirection is specifically broken, but I always use version 2.9.7349.30108
I’ve followed these steps but have run into an issue. The Teams Cache folder are excluded from FSLogix, and Teams loads normally after it is first deployed. After I restart the server and sign back in, Teams does not load and I have to clear the Teams cache completely before it will sign back in.